

When most people think of PR, they think of people, pitches, press events, and storytelling. But what powers modern PR isn’t just relationships. It’s systems. Quiet, invisible, always-on system designs. Distributed queues. Event logs. Monitoring dashboards. Message brokers.
If that sounds like dev-speak, it should. Today’s communications teams operate real-time pipelines, especially in crisis scenarios, viral campaigns, or global outreach efforts. PR tech stacks need to function more like resilient digital infrastructure than a glorified media list.
PR teams are being asked to scale their impact, automate outreach, and monitor public sentiment across dozens of channels 24/7. Without system design principles underpinning your workflows, your campaign might look good until it breaks.
This is the new reality of modern communications: you’re only as fast, adaptive, and reliable as the infrastructure you run on.
The Problem: PR Is Moving Faster Than Our Tech

From Daily Briefings to Millisecond Expectations
Crisis moments don’t wait for team standups. Earned media now lives side-by-side with algorithmic feeds, influencer chatter, and platform volatility. And when things move this fast, traditional PR tools, those built for static workflows, start to fall apart.
Common pain points include:
- Monitoring dashboards that lag behind real-time events.
- Pitching systems that don’t scale during high-volume campaigns.
- Reports that can’t correlate coverage with performance.
- Alerts that flood inboxes without context or prioritization.
What’s missing is architecture. These systems weren’t built to adapt, integrate, or operate at internet speed.
That’s where modern system design principles come in.
Principle 1: Distributed Systems Enable Real-Time PR
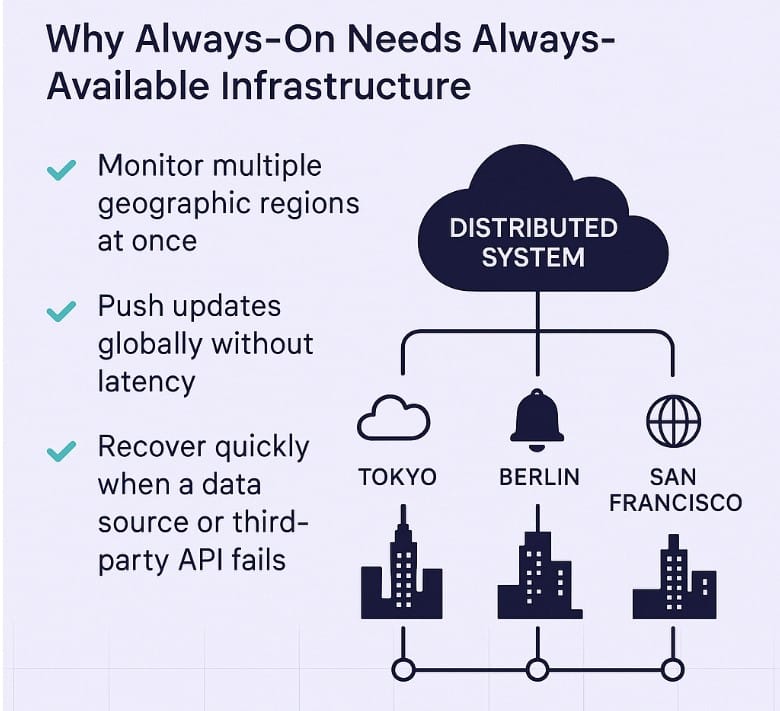
Why Always-On Needs Always-Available Infrastructure
In software architecture, distributed systems solve for uptime, regional scaling, and fault tolerance. In PR? That translates into systems that can:
- Monitor multiple geographic regions at once.
- Push updates globally without latency.
- Recover quickly when a data source or third-party API fails.
Consider a global brand managing simultaneous press events in Tokyo, Berlin, and San Francisco. Distributed logging and monitoring ensure that coverage spikes, sentiment changes, or errors in one region don’t affect another.
In action: A truly global PR workflow uses:
- Geo-distributed news scrapers.
- Time-zone aware alerting systems.
- Regional language NLP models for sentiment tracking.
If your system goes down in a region, does your team even know? If not, you’re flying blind.
Principle 2: Message Queues Keep Campaigns Flowing
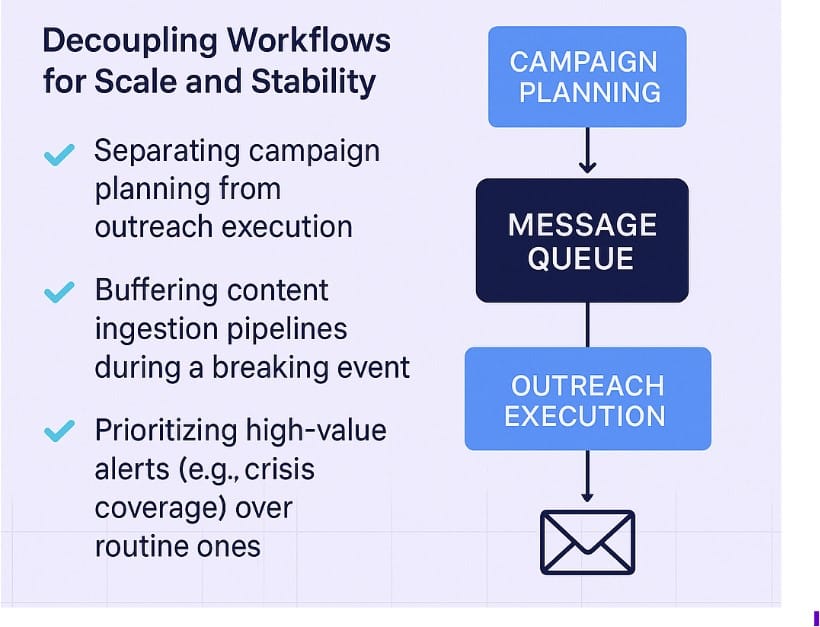
Decoupling Workflows for Scale and Stability
Message queues like Kafka or RabbitMQ are the unsung heroes of scalable software systems. They absorb load, enable asynchronous processing, and decouple systems that would otherwise collapse under mutual dependency.
In a PR context, this could look like:
- Separating campaign planning from outreach execution.
- Buffering content ingestion pipelines during a breaking event.
- Prioritizing high-value alerts (e.g., crisis coverage) over routine ones.
When your campaign sends 1,000 press releases to segmented lists, a queue-based workflow ensures that failures in one segment don’t stall the entire operation. If a single node (or journalist CRM sync) goes down, the rest keep flowing.
Pro tip: Implement priority queues for media mentions. Not all coverage is equal, and neither should your system’s response be.
Principle 3: Observability Turns Panic into Precision
You Can’t Fix What You Can’t See
Monitoring is a survival feature. Yet most platforms only offer surface-level metrics: opens, mentions, and sentiment scores.
In system design, observability means more than logs. It’s about making internal states visible. Applied to PR:
- Can you trace why a sentiment score dipped across five platforms?
- Do you know which pipeline dropped 20% of your Instagram data?
- Can your system differentiate between an actual data outage and an API throttle?
Best practices for PR observability:
- Implement tagging for all incoming media data.
- Use distributed tracing to follow a story’s journey from pitch to coverage to report.
- Create visual heatmaps of media impact over time.
If you’re still reacting to broken reports instead of investigating root causes, your system isn’t observable, but it’s opaque.
Principle 4: Fault Tolerance Protects the Message
Redundancy Isn’t Wasteful—It’s Resilient
System architects know this well: when (not if) a component fails, the system must continue. The same applies to PR workflows.
Imagine you’re managing a product recall and your sentiment tracking tool crashes mid-response. Or your influencer feed silently stops ingesting TikTok content. If your system doesn’t account for these failure modes, your comms strategy is flying without instruments.
Elements of fault-tolerant PR workflows:
- Automatic failovers for monitoring tools.
- Backup pipelines for social media ingestion.
- Graceful degradation (i.e., show partial data, not empty states).
You don’t need 100% perfection, but you do need predictable behavior when things go wrong.
Principle 5: Event-Driven Architecture Makes PR Responsive
Reacting to the Right Thing, at the Right Time
In modern software, event-driven systems react to changes, like a user action or system trigger, rather than constantly polling.
PR teams can adopt the same model:
- Trigger alerts only when sentiment thresholds are crossed.
- Launch workflows automatically when a VIP responds on social.
- Initiate outreach sequences when competitor coverage spikes.
This is the opposite of the old “check everything every hour” model. It’s efficient, contextual, and scalable.
Examples of PR events worth automating:
- Journalists opening press releases (but not replying).
- High-authority outlets mentioning your brand.
- A sudden drop in share-of-voice compared to competitors.
Systems that wait are too late. Event-driven design puts PR on the front foot.
The Future State: Adaptive, API-Driven PR Workflows
Composable Systems, Not Monolithic Platforms
The most powerful PR stacks in 2025 won’t be single tools. They’ll be networks of interoperable services, each tuned for a specific job, communicating via APIs, and coordinated by event triggers and queues.
Think of:
- Airtight media list syncs via CRM integration.
- Real-time crisis dashboards pulling from 5+ data sources.
- Alerts powered by custom sentiment models, not generic SaaS thresholds.
The architecture is the foundation.
From Manual to Modular
Rather than relying on a bloated platform that does everything half-well, leading teams will adopt:
- Modular tools that expose clean APIs.
- Systems built on pub/sub models (e.g., media updates trigger alerts).
- Low-code platforms with observability built in.
This is how PR work goes from reactive to adaptive, without burning out your team.
Avoiding the “Shiny But Shaky” Trap
It’s tempting to chase the latest UX or the newest AI writing assistant. But if the underlying infrastructure can’t support PR’s real-world workflows, all the polish in the world won’t matter.
Red flags in PR tools:
- “Real-time” dashboards with no refresh interval display.
- Tools that crash during viral coverage spikes.
- Platforms that hide failures instead of explaining them.
- Systems with no retry logic for integrations.
Ask your vendor: “What’s your system’s failure mode during a crisis?” If they don’t have an answer, you already do.
PR Teams as System Designers
Here’s a bold claim: the most effective PR teams in the next 5 years will think like system designers.
They’ll ask:
- What does this tool depend on?
- What happens if it fails?
- How do we scale outreach without losing personalization?
- How do we automate alerts without flooding our inboxes?
They’ll architect their workflows intentionally, prioritizing adaptability, observability, and graceful failure over static process documents and bloated platforms.
This isn’t about turning communicators into coders. It’s about using the same thinking that scaled the internet to scale your comms function.
What This Means for the PR Industry
We’re Not Just Communicating; We’re Operating Systems
PR’s role in business has expanded. We’re now expected to:
- React in real-time.
- Prove ROI with data.
- Scale personalized comms globally.
- Manage multi-channel influence campaigns.
Doing all that requires robust, resilient infrastructure. The best storytelling falls flat when your tools are brittle.
System design principles, such as distributed systems, observability, event-driven workflows, queues, and fault tolerance, are how the tech world handles complexity. And it’s how PR will, too.
We need to build the future of PR not on hunches, but on systems thinking.
Final Thoughts: Every Message Deserves a Reliable System
A great press release is only as good as its delivery. A perfect dashboard is meaningless without trusted data. A smart sentiment alert is only useful if it fires at the right time, and not 20 times in a row.
If you want to build an adaptive, scalable, crisis-resilient PR function, start by thinking like an engineer. Design your comms infrastructure with the same care, precision, and resilience you put into your messages.
Because in 2025, the message is the system. And only the best-designed ones will break through.

