

Data engineering is no longer just infrastructure—it’s what determines which businesses can act on what they know. The next few years will separate companies that can deploy AI reliably from those still fixing broken pipelines, especially as real-time systems and tighter regulations make data integration and management non-negotiable. This article outlines the necessary changes: technical systems that can withstand load, strategic investment decisions, and organizational structures that enable engineers to solve problems effectively. If your data infrastructure can’t support what product teams want to build, everything else is theoretical.
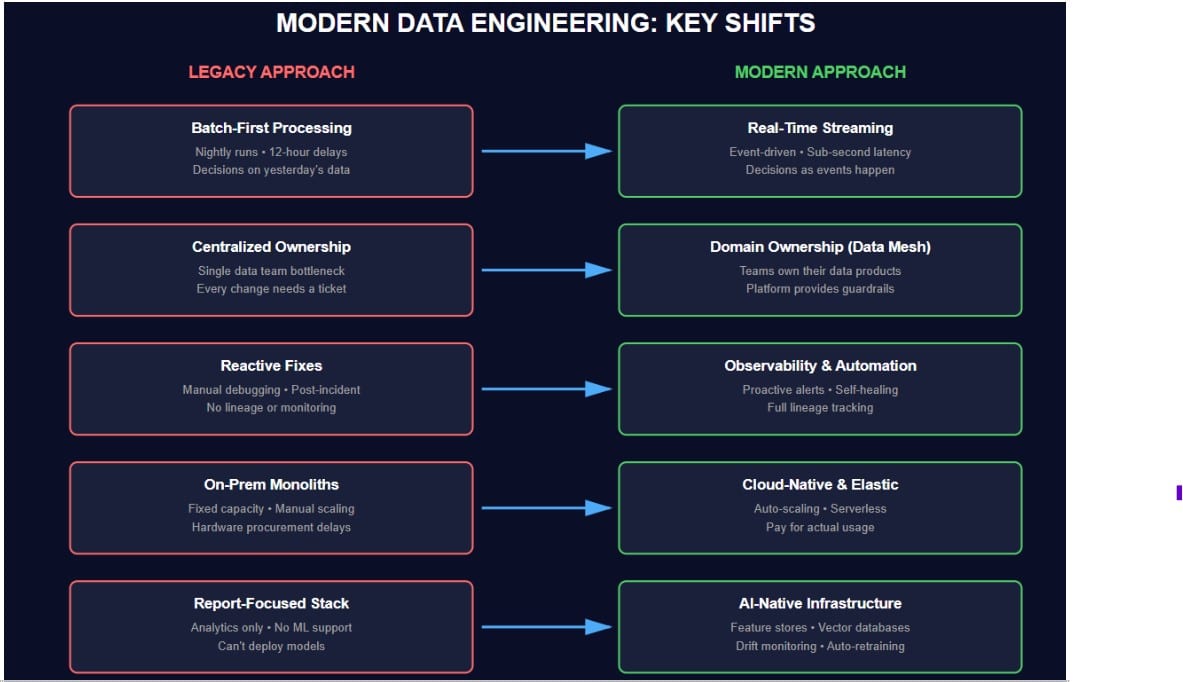
Modern Data Engineering Evolution
What Data Engineering Needs to Do Next
Data infrastructure either supports what your product teams want to build or becomes the reason they can’t ship. The next few years force a choice: real-time systems that handle AI workloads under regulation, or pipelines that keep breaking while competitors move faster. This maps out what actually needs to change—technical, strategic, organizational—before the gap becomes permanent.
Streaming Replaces Batch as The Starting Assumption
Batch processing was once the default due to expensive storage and overnight computing. Now systems expect data to move continuously—events flow from source to destination without waiting for a schedule. Businesses need fraud checks that run during the transaction, not twelve hours later. Recommendation engines update in real-time as users click, and inventory counts reflect what’s in stock. The shift is that decisions made on stale data are outweighed by decisions made on the current state.
AI Workloads Brake Systems Built for Reports
Most data infrastructure was designed to answer questions about what already happened. Machine learning requires something different—pipelines that detect shifts in input patterns before predictions start failing. Feature stores must return values quickly enough to prevent API calls from timing out. GenAI adds vector databases, retrieval systems that can’t go stale, and prompt contexts pulled from five different sources in under 200ms. Teams prototype AI features easily. Keeping them running is where most fail—the data stack wasn’t built for this.
Ownership Moves Out of The Center
Central data teams become bottlenecks when every schema change needs a ticket. Domain teams understand their data better—they know what breaks, what drifts, what matters.
Data mesh principles push responsibility outward:
- Product teams own their data as a product
- Platform teams provide tooling, not approvals
- Central governance sets standards, not workflows
- Self-service becomes possible when guardrails exist
This works when domains can deploy without waiting. It fails when every team rebuilds pipelines from scratch and does it badly.
Regulations Demand Systems, Not Spreadsheets
GDPR was early. What’s coming is stricter and more complex to retrofit. Tracking lineage across ten systems manually is impractical—someone forgets, documentation becomes outdated, and audits reveal gaps. Governance now means automated lineage from source to output, retention enforced in code, audit logs that prove access, and compliance checks that stop bad data before it moves. Fines scale with revenue. Privacy violations kill trust permanently.
Complexity Outpaces What Humans Can Check
Modern stacks involve dozens of tools. Data passes through five systems before it is used. When something breaks, tracing the cause takes hours—if it happens at all.
Automation and observability fill the gap:
- Schema checks that catch breaking changes before deploy
- Cost alerts when a query burns $300 in ten minutes
- Drift detection on model inputs and pipeline outputs
- Lineage maps that show where bad data was entered
- Incident tools that surface root cause, not surface errors
Manual verification doesn’t scale. Systems grow faster than oversight capacity.
These Trends Hit at The Same Time
Real-time systems generate a higher volume of events to process. AI features require infrastructure that most teams lack. Decentralization multiplies the number of pipelines running. Regulations require tracking that wasn’t built in from the start. Each change adds complexity—and without automation, it means things break quietly until someone notices revenue is wrong. Companies that adapt now will ship products that competitors can’t match. Those who wait will spend years fixing foundations instead of building features.
Technologies That Change What You Can Build
Real-time processing, decentralized ownership, and automated monitoring aren’t upgrades—they’re different architectures solving problems the old stack couldn’t. Modern data infrastructure for generative AI needs vector lookups under 200ms, retrieval that doesn’t lag a day behind, and drift detection before predictions break. Companies run batch jobs nightly, but they often struggle to ship features that require live streams and instant responses.
Data Mesh & Domain-Centric Architecture
- Centralized teams become bottlenecks because every schema change is queued, and domain experts cannot proceed without tickets.
- Data products with clear ownership: Teams manage datasets like APIs—versioned, documented, and maintained by people who understand the logic.
- Autonomy that scales: Domains deploy without waiting. Platform teams provide tooling and guardrails, not approvals.
- Decentralization that works: Self-service functions effectively only when infrastructure enforces standards automatically.
Data Observability & Monitoring
- Proactive detection replaces firefighting: Systems catch drift, schema breaks, and cost spikes before users report problems.
- Reduced downtime: Alerts trigger when pipelines slow down, not after they’ve been broken for six hours.
- Automatic cost control: Queries that burn budget get flagged. Storage growth anomalies surface immediately.
- Trust through transparency: Lineage shows exactly where data came from and what touched it.
Automation & AI Ops
- Self-healing pipelines: Dead letter queues to handle bad records. Retry logic recovers from transient failures without manual intervention.
- CI/CD for data transformations: Schema changes get tested before deployment. Breaking changes get caught in staging.
- Anomaly detection on metrics: Models flag distribution shifts. Cost predicts warn before budgets blow up.
- Infrastructure that adapts: Autoscaling responds to actual load—retraining triggers when performance drops.
Cloud-Native & Hybrid Infrastructure
- Modular components that scale independently: Storage, compute, and orchestration grow based on need, not architecture limits.
- Serverless pipelines: Event-driven functions process data without managing clusters or provisioning capacity.
- Managed storage layers: Object stores, warehouses, and lakes interoperate without custom ETL glue code.
- Hybrid flexibility: On-prem sources connect to cloud processing without rebuilding everything at once.
Real-Time and Event-Driven Pipelines
- Decision speed defines competitive advantage, particularly in fraud checks during transactions. Recommendations that update as users browse. Inventory is accurate to the second.
- Streaming-first architecture: Kafka and event APIs handle continuous data flow instead of waiting for batch windows.
- Warehouse-to-lakehouse evolution: Query engines run on raw streams. Storage formats support both analytics and real-time access.
- Latency as a product requirement: Features that depend on stale data are outperformed by features that react immediately.
Making Infrastructure Ready for What’s Next
Preparing technically means more than buying tools. It’s migrating storage, enforcing governance that scales, integrating AI where it solves actual problems, and building systems that don’t fall over when load doubles. Teams often skip steps, adding streaming before fixing lineage or adopting AI without monitoring drift. The order matters.
Move Storage and Compute to Where They Work Better
Cloud or hybrid setups let you scale processing without waiting on hardware. Lakehouse architectures unify analytics and streaming, eliminating the need to duplicate data between systems. Tooling for orchestration, streaming, and elastic compute enables pipelines to adjust to load automatically, rather than crashing at peak traffic.
Build Governance That Enforces Itself
Standardized metadata and lineage tracking show where data comes from and who changed it. Access control stops unauthorized queries before they run, not after someone notices in an audit. Compliance for new regulations needs infrastructure that logs usage and enforces retention automatically—spreadsheets and policies don’t survive a review.
Integrate AI Where It Improves Operations
AI can enrich data during ingestion, flag quality issues before they corrupt models, and answer queries in natural language. Building the foundation now means feature stores, vector databases, and monitoring that catches drift. Teams prototype AI features but struggle to keep them deployed due to a data stack that isn’t built for continuous serving and retraining.
Design Systems That Survive Production
Infrastructure as code means you can rebuild environments without tribal knowledge. Modular automation handles schema changes, retries failed jobs, and scales compute when traffic spikes. Elasticity keeps costs predictable—resources grow with demand, not worst-case estimates that waste budget when load drops.
Building Teams That Can Use This Stuff
Technical readiness means nothing if the org structure fights it. Engineers now need platform thinking, not just ETL scripts. Companies upgrade their tools but leave roles and incentives unchanged, only to wonder why adoption stalls.
Engineers Shift from Moving Data to Owning Platforms through modern data engineering consulting practices
BI analysts used to build reports. ETL developers moved data on schedules. That’s not enough anymore—someone needs to own the platform that serves features to models, handles streaming at scale, and monitors drift. New skills matter: MLOps for keeping models deployed, FinOps for controlling cloud spend before it doubles, governance engineering that enforces compliance automatically. The job is building systems that other teams depend on without breaking.
Data Work Becomes a Shared Problem
Product teams can’t simply hand over requirements and then wait for datasets. Data engineers need to think like product owners—considering what breaks, what drifts, and what users need. Departments need data stewards who understand their domain logic and can identify and prevent bad transformations from corrupting downstream work. Collaboration happens when both sides own the outcome. It fails when engineers build what was asked for but not what was needed, or when business teams blame “bad data” without understanding where it came from.
Quality Becomes Everyone’s Job
When only one team cares about data quality, nothing improves. Empowered teams own their pipelines, catch issues early, and fix what they break. Accountability means product teams can’t ship features based on stale data and then blame the infrastructure. Engineering can’t ignore schema changes that crash business logic. Friction drops when technical and business units share responsibility for outcomes, rather than just their piece of the pipeline. Trust builds when people fix problems instead of pointing at who caused them.
Strategy That Survives Contact with Reality
Business goals and data infrastructure must connect; otherwise, one becomes theoretical. Leaders say they want faster decisions and new products, then underfund the systems that make those possible. Strategic readiness means knowing where to invest first, what GenAI actually requires, and how data stops being a cost you tolerate.
1. Connect infrastructure to outcomes that the business measures
Faster decision cycles need pipelines that don’t wait for batch windows. Cost reduction comes from query optimization and storage tiering. Product innovation stalls when teams can’t access clean data without filing tickets—data becomes a service when other teams can use it without asking permission.
2. Prepare for GenAI and real-time before you need them
LLMs require retrieval pipelines that remain current and vector stores capable of handling lookups. Real-time analytics for operations means streaming architectures, not dashboards that refresh hourly. Personalization dies when recommendations lag user behavior by twelve hours—preparation means building the stack before product teams want to ship features that depend on it.
3. Invest in order: foundations, wins, bets
Start with foundational upgrades—governance, lineage, observability—because everything else breaks without them. Quick wins prove value: cost monitoring cuts cloud spend by 30% and automated testing catches schema breaks. Long-term bets—such as AI ops and streaming-first architectures—pay off later, but only if the foundation holds.
What to Do First, Next, and Later
Companies often try to fix everything at once, resulting in half-built systems that don’t work together.
Short-term (0–6 months)
- Audit what you have—map pipelines, identify where data breaks, and measure the time it takes to debug incidents.
- Set up lineage tracking and metadata catalogs to visualize dependencies before making changes.
- Add observability: cost monitors, schema validators, and drift detection on critical models.
Mid-term (6–18 months)
- Automate schema testing, retry logic, and dead letter queues—stop fixing the same pipeline failures manually.
- Build streaming infrastructure for workloads that can’t wait on batch windows: fraud checks, recommendations, and inventory.
- Move compute to cloud or hybrid setups, where you can scale processing without waiting on hardware procurement.
Long-term (18–36 months)
- Decentralize ownership so domain teams manage their own data products with platform guardrails, not central approval queues.
- Deploy AI-native stack: feature stores, vector databases, automated retraining triggered by drift metrics.
- Ship internal AI products that depend on clean, fast data—search tools, copilots, predictive models that stay accurate past launch.
The Window Is Now
Companies that invest in infrastructure over the next two years will ship products that others can’t match. Those who wait will spend 2027 rebuilding foundations, while competitors launch features that require real-time data and deployed AI. Readiness beats reaction—you can’t retrofit governance into a system already under regulatory audit, or bolt streaming onto pipelines designed for nightly batches. The gap between what modern products require and what legacy stacks deliver is widening. Build now or explain later why you’re still catching up.
