

4 questions covered in this article:
- How can AI and humans work together to reduce noise in media monitoring?
- Which 2025 audience trends matter most for setting alert thresholds?
- How should teams design a human-in-the-loop workflow from triage to decisions?
- Why use a free proxy in the intake layer, and how does it help?
Media teams in 2025 have more inputs than ever, and with less time to make sense of them. Newsrooms and brands follow breaking updates, creator posts, and fast-moving talks across platforms. At the same time, people are changing how they find news, and trust is still shaky. That mix leads to a simple question that is tough to answer in real life: how do you highlight the signal and cut the noise without tiring people out or missing what really matters?

Source: Here
The attention problem in 2025, by the numbers
The hybrid model works best when it is grounded in current audience behavior. A few recent figures capture the shift. Global trust in news holds near 40 percent. In the United States, more people now say social and video networks are their main source of news than TV or news sites. On platforms, Facebook and YouTube still lead as regular news sources. Many adults also report using AI to search for information. Trust in media, as a broad institution, sits near the low-to-mid fifties globally. These signals explain why monitoring needs both scale and care: the conversation can start anywhere, travel fast, and reach people who may doubt what they see.
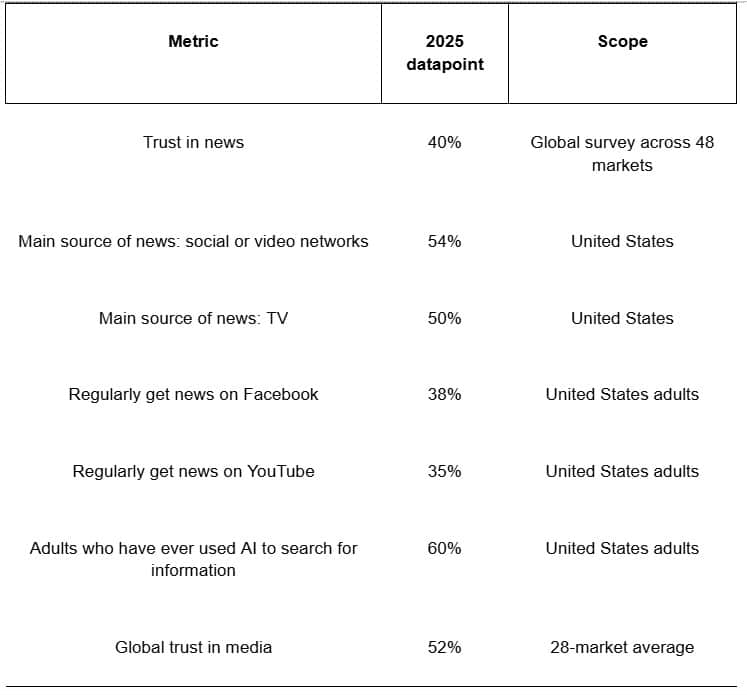
These numbers suggest a practical setup. Give AI the first pass on social and video content, since that is where attention concentrates. Weight alerts by source reach and duplication, not just by volume. Tie thresholds to business outcomes rather than vanity counts. Most of all, close the loop between AI findings and human checks. When trust is delicate, final judgment still belongs to an editor who can weigh tone, context, and likely impact.
From triage to decisions: designing a human-in-the-loop workflow
A good workflow turns raw intake into decisions that hold up under scrutiny. Start with a shared brief that defines topics, entities, and risk levels. Let the model tag matches, cluster duplicates, and draft two-line summaries. Route high-risk or high-reach items to a human queue. Keep a short, consistent rubric for reviewers so decisions are fast and comparable. Then capture outcomes to retrain the model on what your team values.
Adoption data shows the direction of travel. In a recent industry survey, 87 percent of media leaders said newsrooms are being fully or somewhat transformed by generative AI, which is also actively used in the corporate world. Publishers also plan to invest in audience-facing features such as text-to-audio, automated summaries, and translations, with reported focus levels around 75 percent, 70 percent, and 65 percent. These figures align with a stack where automation does more of the repetitive work, and humans focus on nuance and calls to action.
One line sums up the moment. As Nic Newman of the Reuters Institute put it, “The way audiences access news is likely to change significantly in the next few years and that will require publishers to rethink their strategies around content, products and distribution.” Treat that as a design brief. Build for change, not for one platform’s feed. Measure recall and precision in your alerts. Track reviewer agreement as a quality metric. When you ship an insight to executives, include source links, the model’s confidence score, and a one-sentence human note on why it matters now. That small bundle is what turns noise into signal at speed.
Build a resilient intake layer with free proxy as the anchor
For many teams, the intake layer starts with web requests and a free proxy can be surprisingly useful. In media monitoring, you often need to fetch pages from many domains, hit rate-limited endpoints, or see how posts render from different locations. A proxy routes your requests through other IP addresses so you can diversify sources and reduce throttling. Used well, it becomes a small but vital part of a larger data pipeline.
Think of three mechanics. First, variety. Rotate IPs and locations to sample content that changes by region, such as trending lists or geo-gated embeds. Second, persistence. Keep session affinity when a site needs a cookie trail to reveal the same feed you saw a minute ago. Third, restraint. Set polite request intervals, respect robots.txt where applicable, and cap concurrency so your crawler stays steady. Even basic HTTP or SOCKS proxies can support these steps when paired with smart scheduling and caching.
On implementation, keep headers and identities clean. Randomise user agents within a safe set, and pass only what you need. Use connection pooling to keep latency predictable. Log just enough to trace issues, then rotate keys on a routine schedule. Most monitoring jobs are read-only, so the main risks are reliability and consistency, not data exposure. A simple health check, a fallback route, and alerting on timeouts will cover most problems.
Where does a free proxy fit economically? Use it for low-risk discovery, freshness checks, and lightweight spot tests on new sources. It can also fill gaps while you evaluate a bigger network. When volume rises, move the heavy traffic to a more robust pool and keep the free tier for experiments and QA. This keeps costs sensible without locking you in early. If you want an example of a service that teams try in this phase, you might look at Webshare at the end of your evaluation list, then decide if it suits your mix.


{kind=link}