

Despite the promise of artificial intelligence, many AI business initiatives seem to keep running into roadblocks. In a new survey from enterprise machine learning (ML) platform Comet, hundreds of ML practitioners were asked about their experiences and the factors that affected their teams’ ability to deliver the level of business value their organizations expected from ML initiatives. Rather than attaining desired outcomes, however, many survey respondents revealed that they lack the right resources, or they shared that the resources they have are often misaligned. As a result, many AI initiatives have been far less productive than they could be.
Issues include the fact that many experiments are abandoned because some part of the data science lifecycle was mismanaged. This is due in large part to the manual tracking processes that organizations often put in place, which hinder effective team collaboration, and are not adaptable, scalable, or reliable. Of models actually deployed into production, nearly one quarter failed in the real world for more than half (56.5 percent) of the companies surveyed. As such, the full business value of machine learning is rarely captured.
“There has been so much enthusiasm around AI, and ML specifically, over the past several years based on its potential, but the realities of generating experiments and deploying models have often fallen well short of expectations,” said Gideon Mendels, CEO and co-founder of Comet, in a news release. “We wanted to look deeper into where the friction lies so that issues can be addressed.”
According to survey respondents:
Significant time, resources and budgets are being wasted
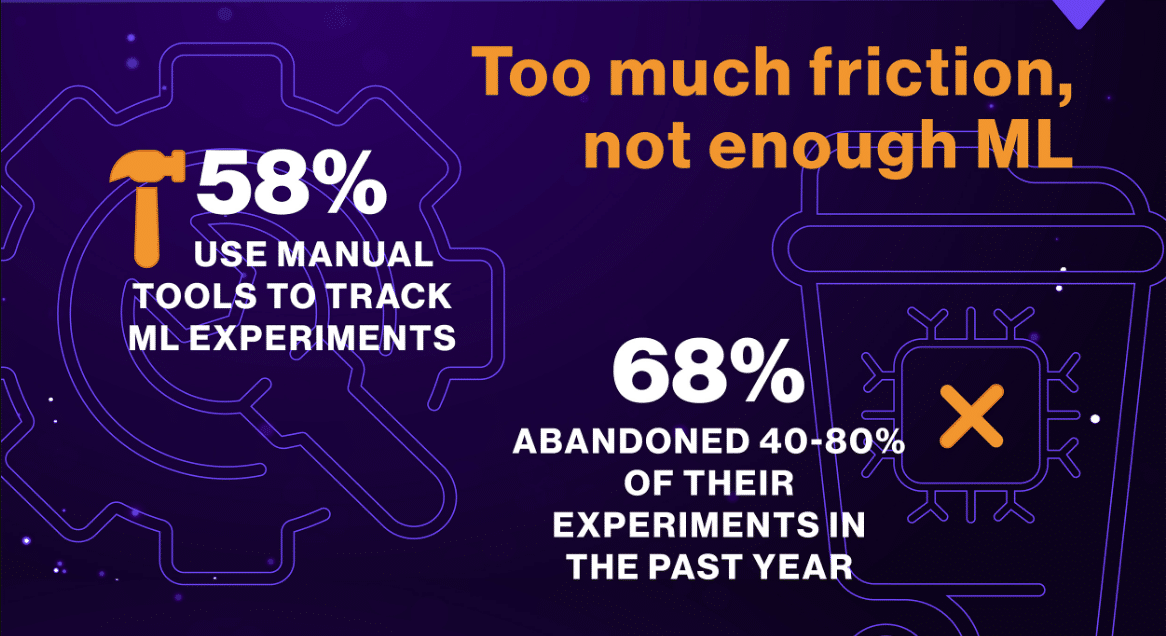
While teams expect to run, adjust, and re-run experiments as part of model development, 68 percent of respondents admit to scrapping a whopping 40-80 percent of their experiments altogether. This was due to breakdowns that occur throughout the machine learning lifecycle outside of the normal iterative process of experimentation.
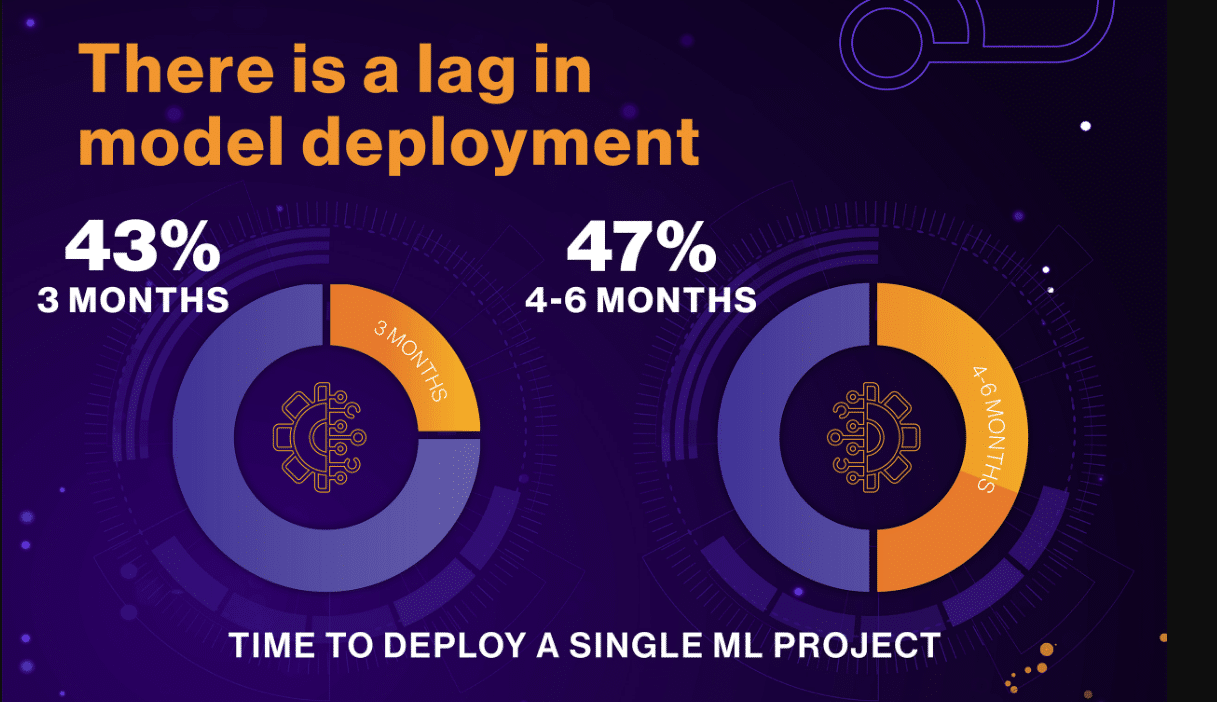
There is a serious lag in model deployment
Only 6 percent of teams surveyed have been able to take a model live in under 30 days. By contrast, 47 percent of ML teams require four to six months to deploy a single ML project, while another 43 percent take up to three months. This can cause unnecessary delays in delivering value to the respective lines of business.

Budgets for tools that could address issues are woefully inadequate
Despite the enthusiasm for ML overall, 88 percent of respondents have an annual budget of less than $75,000 for machine learning tools and infrastructure. This is far less than the average salary for a single data scientist and dwarfed by the opportunity cost resulting from under-investment.

Without funds for automation, ML teams must track experiments manually
In fact, 58 percent of machine learning teams track all or at least some piece of their experiments manually. This places an enormous strain on workers, causes projects to take far longer to complete, creates challenges for team collaboration and model lineage tracking, hinders model auditability, and leads to unintentional mistakes.
Companies are not intentionally withholding budgets or misallocating ML resources
They simply “don’t know what they don’t know,” as ML is still an emerging discipline. Of survey respondents, 63% said their organizations would increase ML budgets for 2022, but whether or not these funds will be devoted to the right tools and resources remains to be seen.
State of enterprise ML today
ML has demonstrated that it can deliver outsized business value and exciting technological innovation, and as such more companies are seeking to apply it, only to find the tools and processes to be nascent, disconnected, and complex. This makes it difficult to collaborate among teams and uncover the insights that drive business forward. Even though many organizations are good at identifying ML use cases and initiating projects, they fall short in investing in ML operations best practices and the tools and resources needed to make these machine learning initiatives as clear, efficient, and scalable as possible.
Developing effective ML models requires a lot of experiments. These experiments can involve changing the model itself or tweaking its hyperparameters. They may utilize different datasets or involve changing code to evaluate how the algorithms behave differently. When developing and training an ML model, all these changes happen repeatedly, sometimes with only minute differences each time. This makes it difficult to keep track of which experiments and which parameters produced which results—including details such as scripts, the runtime environment, configuration files, data versions, hyperparameters, metrics, weights, and more. Poor experiment management leads to the inability to reproduce results accurately and consistently, and it can throw an entire project off the rails, wasting countless hours of a team’s work.
“Even though companies are prepared to allocate more money and resources to ML programs, they must address some core operational issues first if they want to see a positive return on their investment,” said Mendels. “If teams are maxed out and struggling with visibility, reproducibility and cost-efficiency today, it will be difficult for them to add more models, experiments and deployments this year, as they expressed the desire to do. Successful ML outcomes depend on people; and with the right tools, teams can avoid burnout.
“Despite the challenges teams and organizations face, there is good news that tools are advancing rapidly to solve for these problems,” added Mendels. “Leading-edge companies that have implemented modern AI development platforms are realizing the benefits, full potential, and value from their machine learning initiatives, which is quite exciting.”
Additionally, the availability of specialized AI courses is helping organizations upskill their teams, enabling them to leverage these advanced tools even more effectively and drive greater innovation and success.
Comet commissioned an online survey from Censuswide of 508 U.S. machine learning practitioners across industries. Respondents answered multiple-choice questions about ML development and factors affecting their teams’ ability to achieve business value using data and machine learning.

