

For most PR pros, “system design” sounds like something for engineers, not communicators. But in a world where reputation management is inseparable from real-time technology, the health of your media monitoring and outreach systems can make or break your crisis response.
When those systems fail, whether a monitoring dashboard goes down mid-crisis, a distribution tool sends embargoed releases early, or sentiment alerts arrive hours late, the PR consequences can be severe. The meltdown may be technical, but the fallout is reputational.
The reality is that your PR tech stack isn’t just a set of tools. It’s a living system. And like any mission-critical infrastructure, it needs to be designed for resilience.
When PR Tech Breaks, So Does the Narrative
A PR team’s technology footprint typically includes:
- Media monitoring platforms
Tracking brand mentions, sentiment analysis, and emerging narratives. - Media outreach tools
Sending pitches, managing lists, and coordinating follow-ups. - Alerting and escalation channels
Integrations to Slack, email, or SMS for crisis notifications. - Analytics dashboards
Providing performance and campaign insights in real time.
When these systems falter at the wrong moment, the consequences compound quickly:
- A critical mention is missed, and misinformation spreads unchecked.
- A media list error sends private briefings to the wrong journalists.
Delayed alerts mean leadership responds after a negative trend has already gone viral.
In short: system downtime = narrative downtime, and in PR, that’s deadly.
Why System Design Matters for PR Resilience
System design is the blueprint for how your technology operates under normal and extreme conditions. While IT teams often focus on uptime percentages and server load, PR needs to focus on narrative uptime, including your ability to detect, assess, and respond to a story at any moment.
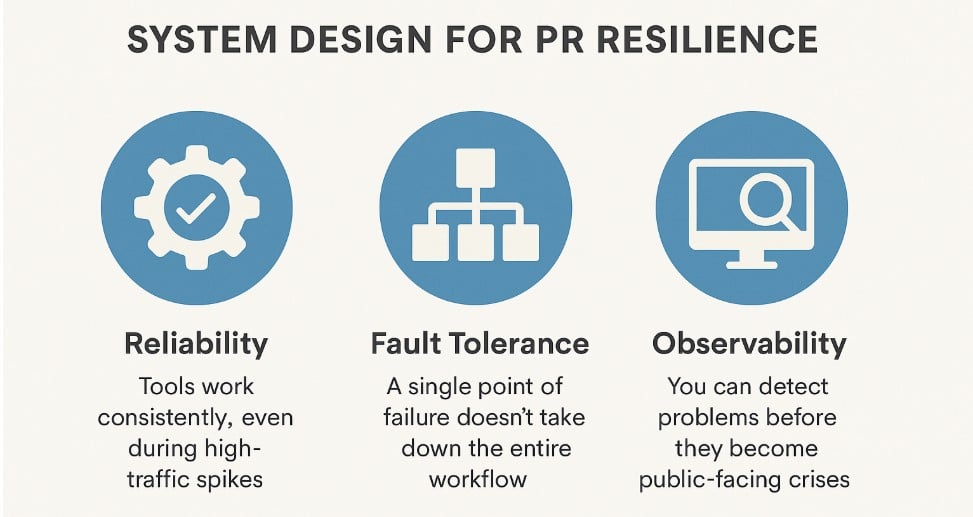
Good system design for PR tech achieves three key goals:
- Reliability: Tools work consistently, even during high-traffic spikes.
- Fault Tolerance: A single point of failure doesn’t take down the entire workflow.
- Observability: You can detect problems before they become public-facing crises.
Think of it as applying newsroom-level redundancy to your comms tech: if the wire goes down, the backup feed kicks in immediately.
Common Failure Points in PR Tech Systems
1. Single Vendor Dependency
If all monitoring, alerting, and outreach functions are tied to one provider, a single outage can cripple your operations.
2. Poor Load Handling
A sudden spike in mentions during a crisis can overwhelm poorly architected dashboards or APIs.
3. Delayed Data Pipelines
Batch processing of mentions or sentiment means you’re always hours behind in detection.
4. Unverified Automation
Automated outreach without fail-safes can result in off-message or mistimed communications.
5. Weak Integration Resilience
If a Slack or email integration fails, critical alerts may never reach the right people.
Each of these weaknesses is a system design flaw, not just a tech glitch.
Designing for PR Resilience: Core Principles
1. Redundancy in Monitoring
Run at least two independent monitoring systems with overlapping coverage. If one fails, the other provides continuity.
2. Real-Time Processing Pipelines
Shift from batch to streaming data ingestion for mentions, sentiment, and trend detection. This will reduce the lag between events and awareness.
3. Distributed Architecture
Use separate infrastructure for monitoring, outreach, and alerting to prevent cascading failures.
4. Graceful Degradation
Design systems to operate in “reduced mode” if a component fails, for example, showing limited data but still surfacing critical alerts.
5. Alert Escalation Chains
Build multi-channel alerting pipelines so that if one channel (e.g., email) fails, another (e.g., SMS or app push) takes over automatically.
The Anatomy of a Resilient PR Tech Stack
Just as a system design interview evaluates an engineer’s ability to architect a fault-tolerant, scalable platform, PR leaders must think about their monitoring infrastructure the same way. They must ensure it can scale during crisis-level traffic spikes and recover quickly from failures. A high-resilience system for PR should resemble a well-architected real-time monitoring platform in other industries.
Core Components:
- Data Ingestion Layer: APIs, scrapers, and feeds pulling from social, news, and broadcast sources.
- Streaming NLP Pipelines: Processing sentiment, topic clustering, and anomaly detection in real time.
- Event Queue & Broker: Tools like Kafka or RabbitMQ managing message flow without bottlenecks.
- Alert & Escalation Engine: Rules-based routing to notify the right stakeholders instantly.
- Fallback Systems: Pre-configured backups for monitoring and outreach platforms.
For an engineering deep dive, see this real-time system design for monitoring and alerting pipelines.
Case Study: Outage During a Product Recall
Scenario:
A consumer brand launched a voluntary product recall. Just as social chatter spiked, their monitoring vendor experienced an API outage. The PR team didn’t see the most viral posts until four hours later.
Impact:
- Media outlets reported on consumer anger without the brand’s context.
- The recall landing page received negative SEO hits from unaddressed misinformation.
- Crisis response time increased by 300%, leading to executive frustration.
System Design Fixes:
- Implemented dual monitoring providers.
- Added SMS alerts as a backup to Slack notifications.
- Shifted to a streaming architecture for high-sensitivity keywords.
Testing and Auditing for PR Tech Readiness
Resilient system design isn’t set-and-forget. PR leaders should mandate:
- Quarterly Load Tests: Simulate crisis-level mention spikes to test throughput.
- Failover Drills: Switch to backup monitoring mid-simulation to ensure team readiness.
- Integration Health Checks: Regularly validate that alert channels (Slack, email, SMS) are delivering in under 30 seconds.
Automation Audits: Review outreach templates and triggers to prevent errors under load.
This testing culture mirrors newsroom “breaking news” drills, keeping teams sharp and systems battle-ready.
- Emb
Best Practices for PR Leaders
ed Tech in Crisis Planning
Your crisis playbook should include technical contingencies, not just messaging protocols. - Own the Integration Map
Maintain a visual diagram of how monitoring, alerting, and outreach systems connect, so you can see potential points of failure. - Budget for Redundancy
Resilience often requires paying for more than one vendor per function. Frame this as insurance, not excess. - Collaborate With Engineering
Don’t silo PR tech decisions. Work with IT to ensure infrastructure meets crisis comms needs. - Review After Every Incident
Treat every tech failure as a learning opportunity for both comms and engineering teams.
What This Means for the PR Industry
The days when PR tech could be a “black box” are over. Today’s communications strategies are inseparable from the infrastructure they run on. As crises become more complex and real-time, system design literacy will be as essential for PR leaders as media literacy.
Brands that treat their monitoring and outreach systems as mission-critical infrastructure, not just SaaS subscriptions, will weather the next PR tech meltdown with their narratives intact.
In the new communications reality, it’s about making sure your systems are capable of delivering that message when the world is watching.

