

Online survey technology has transformed the market research industry. By providing more agile self-service options for programming and executing studies, online surveys have enabled businesses to generate relevant, actionable data more quickly than was previously possible.
The online survey landscape is now poised for an even more profound impact on the research industry. The combination of artificial intelligence (AI), natural language processing (NLP) and crowdsourcing methods has solved the problem of capturing and processing free-text answers to open-ended questions that are widely acknowledged to deliver the most interesting, relevant and valuable insights. By automatically cleaning up, validating and grouping answers in real time, AI-based surveys not only eliminate laborious manual work but also transform the qualitative responses into rich data sets that can now also be used in quantitative analytics.
A side-by-side comparison of two online studies captures the major differences between traditional and new AI-based survey approaches. The baseline study is a web survey conducted by Pew Research, one of the world’s preeminent nonpartisan fact tanks. Using traditional best practices for online surveys, Pew depended heavily on free-text responses to the question “What Lessons do Americans See for Humanity in the Pandemic?” This same study was then re-created using AI, NLP and crowdsourcing technology with our GroupSolver survey platform. While the two delivered similar findings, they differed in the respondent experience as well as the speed and scope of analytics and depth of associated insights.
Pandemic lessons for humanity
Pew first asked each of its 10,211 study panelists, “Do you believe there is a lesson or a set of lessons for humankind to learn from the coronavirus outbreak? And if so, do you think these lessons were sent by God, or not?” All respondents to the survey were part of Pew Research Center’s American Trends Panel (ATP), an online survey panel that is recruited through national, random sampling of residential addresses. Half of the respondents who said yes to the first question were then asked to describe, in their own words, what lessons they think humankind should learn. This prompted written responses from 3,700 people that ranged from a few words to several sentences. Pew then reviewed and synthesized the data into multiple broad, high-level themes.
In the study, we re-created using our combination of AI, NLP and crowdsourcing, the same questions were posed to 445 respondents as part of a larger Covid-19 pulse check study. Rather than asking only a portion of respondents to elaborate on humanity’s lessons as Pew did, the free-text responses were solicited from all participants. Other differences between the two surveys included using “unsure” instead of “no answer” as an option for the closed-ended question and changing the question order so that the one about “lessons sent from God” was asked last and did not prime respondents in any way.
The format for capturing this natural language information using AI-based technology also differed from Pew’s approach. Instead of giving respondents only the traditional text box for entering their unaided text-box responses, as Pew did, AI technology enabled us to ask follow-up questions. These questions were generated by an algorithm that began sampling and quickly processing respondents’ free-text answers as soon as they were entered. The algorithm removes duplicate answers and noise, and only keeps those statements that are unique and meaningful. It then feeds these statements back to respondents in the form of an ad-hoc, dynamic mini-survey. Each respondent is asked to agree or disagree with these statements, and the process is repeated 5-10 times regardless of whether respondent provided unique free-text unaided answer to the original question or not.
There are three advantages to this approach
First, it ensures all respondents contribute data even if it is only their assessment of others’ answers. Second, enlisting respondents to interactively validate and quantify data in real time results in more robust “coded” answers from the study’s natural language input than is possible with ex-post free-text analytics tools. Third, themes are automatically identified and grouped by an algorithm that is trained in real time based on the specific answers being provided by survey participants. It can be calibrated so it fits the specific question at hand as it searches for and groups similarly themed answers. This is a major time-saver for researchers and provides the flexibility to fine-tune theme-coding on the fly by adjusting the algorithm’s desired grouping sensitivity level from least to most specific using a slider sale.
Comparing the results
In the open-ended question section of the two studies where respondents were asked to describe what lessons they thought humankind should learn, the Pew researchers surfaced broad, high-level themes from these free-text answers that they grouped into practical lessons as well as those about God and religion, society, life and relationships, and government and politics. They also selected and shared a sampling of respondent quotes in each category.
While this is the typical process of summarizing and reporting answers to open-ended questions, it can be difficult for researchers to judge response nuances and how to group them. The AI-based GroupSolver platform eliminated this step. After filtering out noise, gibberish and unclear free-text answers, machine learning (ML) technology was used to automatically consolidate the survey responses. Advanced statistics validated the natural-language answers and themes were automatically grouped without requiring any manual work or subjective judgments. The themes, in the respondents’ own voice, also tended to be more specific, as shown in Figure 1.

Figure 1: Respondents’ answers to the prompt were automatically grouped into broader themes in the re-created study using the GroupSolver platform, without requiring any manual processing.
From here, AI-based technology moved the study straight to insights. This included analyzing how much support strength there was for the statements that were provided and then validated by the respondents during this process (see Figure 2).

Figure 2: Statements representative of the group were automatically created and fed back to respondents through an ad-hoc dynamic survey to determine the extent to which they collectively agreed or disagreed with them.
This interactive validation process created rich quantified data sets of natural language answers that could now also be used in traditional quantitative analysis. For example, segmentation tools were used to explore how support strength for statements differed between various groups of respondents. It became clear that Democrats believe a lesson humanity should learn revolves around “listen[ing] to science” (89 percent of Democrat respondents supported this statement). On the other hand, Republicans seemed to support the idea that “Democrats are trying to keep American workers down” (70 percent of Republican respondents supported this statement). Statements such as “take nothing for granted” had 89 percent support strength among all segments (see Figure 3).
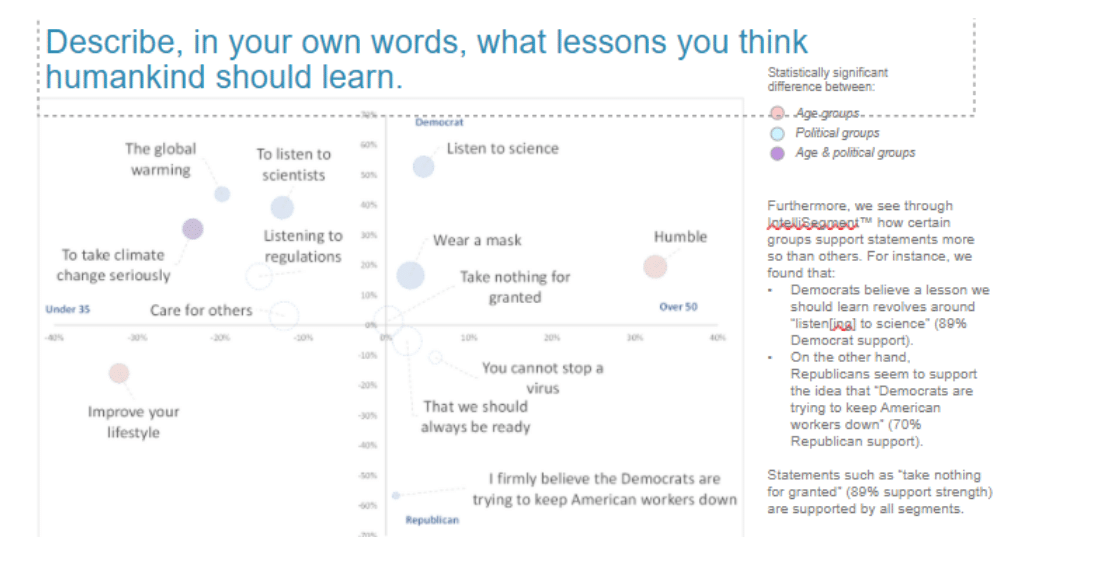
Figure 3: A segmentation analysis discerned differences in levels of support for statements based on political party affiliation.
Other insights were derived from visualizing the data in two ways (Figure 4). The chart on the left provides an alternative look at the most supported answers to the Pew study’s open-ended questions. Larger font denotes a higher support strength. The chart on the right is a cluster analysis of the natural language data that shows correlations between these open-ended answers, something that would traditionally be reserved for quantitative studies.
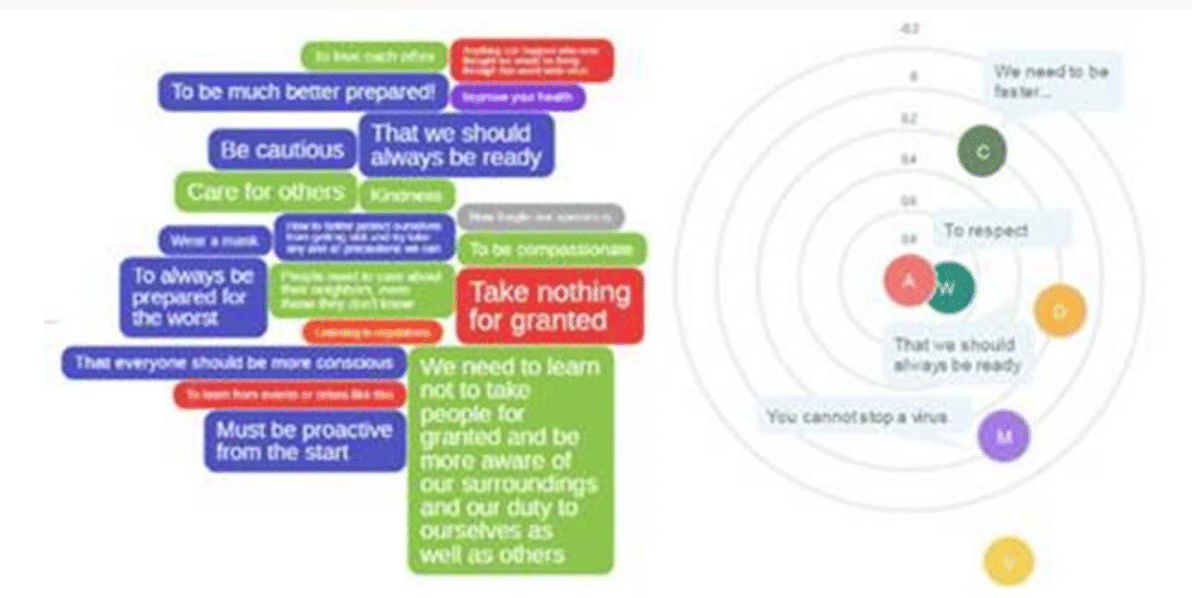
Figure 4: Additional visualization options give researchers more ways to surface insights, including support strength (on the left) and correlations (on the right).
The tale of two approaches
While there were some differences between the two studies, similarities also emerged. For instance, most would agree that there are a set of lessons that humankind can learn from COVID-19, and this sentiment was fairly split between those who do believe that these lessons were sent from God versus those who do not.
Beyond these similarities were a host of additional benefits that become available using the smart survey technologies. First, knowing respondents’ support strength for various themes and statements allowed researchers to tell their story with more confidence. Second, the statistically validated qualitative data that had automatically been grouped into themes could now be used in additional types of analyses. These benefits are available to other researchers conducting a variety of work ranging from net promoter score (NPS) and pricing studies to in-depth product testing where natural text data becomes become categorical variables in quantitative models.
Also important to researchers is the speed of output delivery using the AI-based approach. Since algorithms run in real time, output is available as soon as respondents start providing answers. With minimal to no post-processing or further data manipulation required after the study is complete, the results are ready in minutes. A traditional study similar in size to the Pew survey would typically require days of work to clean up data and find consistent themes that express the sentiment of the respondent group.
Finally, there is the respondent experience to consider. The added benefit of an AI-based platform’s gamified interactive survey process is that it is more enjoyable for respondents. One GroupSolver client surveyed its customers to see how strong this appeal was, and 70 percent of respondents said they prefer the experience to that of a traditional survey. This is important for researchers to know since more engaged and attentive respondents deliver higher-quality responses.
What’s ahead
The growing adoption of AI and other advanced survey technologies means fewer researchers will need to gravitate to closed-ended questions just to avoid manually processing massive amounts of raw, unorganized free-text data. Smaller businesses and marketing organizations won’t need the same labor pool as larger research firms to ask high-value open-ended questions, and this will move the industry from simply “talking” at respondents to a much more effective listening mode . Researchers will also be able to do more with this data as they not only “hear” each respondent’s voice but also gain deeper and more meaningful insights from it. Finally, these smart survey technologies lend themselves to a variety of tiered online offerings and delivery models, with the potential to make easy-to-conduct, high-quality on-demand research studies of any size accessible to a much larger user base, across a significantly broader range of applications.

